Current plans for contact-tracing are based around mobile phones, because these have built-in capabilities for location tracking and contact detection. An alternative to mobile phones for contact-tracing would be a… Read more »
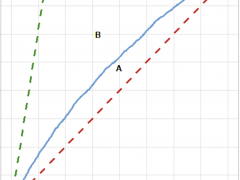
Each contact you have with another person potentially infects you with a virus. If the person you have contact with later tests positive for that virus, the contact you had… Read more »
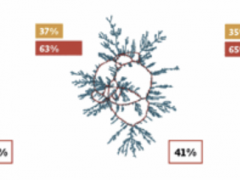
As our team was designing and implementing an open API for COVID-19 contact-tracing, we also created a smartphone app to demonstrate how fully-anonymised automated contact-tracing can be done with a… Read more »
Contact-tracing is one of the most useful tools in the fight to control the spread of a virus. Authorities in China, Singapore and South Korea have successfully deployed contact-tracing as… Read more »
As I have just joined the team at Armstrong Consulting, I was encouraged to explore the capabilities of Solr within a Docker container and research ways to index existing data… Read more »
To familiarize ourselves with all the technologies we will be using day-to-day, we wanted to create an application using as many of them as possible as an exercise. In this post we are going to outline the steps to recreate that application.
This blog was running on WordPress on a dedicated Ubuntu 14.04 VM host. When I tried to update the host to Ubuntu 16.04, I broke WordPress. Rather than trying to… Read more »
We typically deploy REST APIs behind a HAProxy reverse proxy. We often need to enforce SLAs and protect those APIs from being flooded with too many concurrent requests. In this… Read more »
Introduction We often need a simple web server as a Docker container to serve up static content (HTML or an Angular app etc) or a minimal php web app. So… Read more »
Introduction In this workshop, we’re going to define a REST API and implement it in Java. Furthermore, we’re going to do it using the API-first methodology, which means we’re going… Read more »